[Spark] Spark DataFrame 개념 정리!
<Spark Dataframe 개념 정리>
안녕하세요.
저번 시간, Spark RDD에 이어,
스파크의 두번째 데이터 구조인 DataFrame 으로 돌아온,
개발자 김모씨입니다.
혹시 스파크의 가장 기본적인 데이터 구조인 RDD를 설명하는 포스팅을 아직 보지 않으신 분들은(!)
얼렁 다녀오시죠!
artist-developer.tistory.com/17
[Spark] Spark RDD(Resillient Distributed Data)란?
안녕하세요. RDD란? 이라는 글로 돌아온, 개발자 김모씨입니다. 오늘은 스파크의 데이터 구조인 RDD에 대해 알아볼 건데요. 스파크는 기본적으로 RDD들의 흐름에 의해 동작한다고 보시면 됩니다. ��
artist-developer.tistory.com
저번 포스팅에서 스파크의 데이터 구조는 크게
- RDD (Resillient Distributed Data)
- DataFrame
- Dataset
세 종류로 구분할 수 있다고 말씀드렸죠.
RDD는 Spark v1.0 부터 도입된 가장 기본적인 구조라면,
DataFrame 은 Spark v1.3에서 도입된 데이터 구조입니다.
(DataFrame의 별칭은 SchemaRDD 입니다. 왜 그럴까유? 글을 읽기 전 먼저 예측해보세유)
그럼,
- Spark 진영에서 왜 DataFrame 이라는 개념을 새로 도입했는지
- DataFrame이라는 데이터 구조를 썼을 때 얻을 수 있는 Benefit이 무엇인지
두 가지가 핵심이겠죠?
지금부터 알아봅시다.
DataFrame의 등장 (Feat. RDD의 문제점)
혹시 DataFrame 이라는 단어를 보고,
Python pandas의 dataframe이나 R의 dataframe을 생각하신 분 계신가요?
아니면...SQL의 Data Table을 먼저 떠올리신 분들 계신가요?

맞습니다. 비슷한 개념이에요.
스파크의 DataFrame은 행과 열로 구성된 데이터 분산 컬렉션 입니다.
쉽게 말하면, 더 나은 최적화 기술을 가지고 있는, 관계형 데이터 베이스 구조라고 할 수 있겠죠.
그렇다면, RDD가 있었음에도 불구하고 Dataframe이라는 새로운 데이터 구조 API가 등장한 걸까요?
문제는 RDD의 성능적 이슈에 있었습니다.
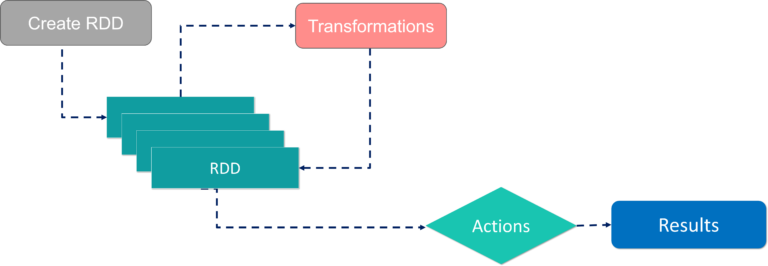
- RDD는 메모리나 디스크에 저장 공간이 충분치 않으면 제대로 동작하지 않습니다.
- RDD는 스키마(데이터베이스 구조) 개념이 별도로 없습니다.
구조화된 데이터와 비구조화 데이터를 함께 저장하여 효율성이 떨어집니다.
- RDD는 기본적으로 직렬화(데이터를 배포하거나 디스크에 데이터를 기록할 때마다 JAVA 직렬화 사용)와 Garbage Collection(사용하지 않는 객체를 자동으로 메모리에서 해제)을 사용합니다. 이는 메모리 오버헤드를 증가시킵니다.
- RDD는 별도의 내장된 최적화(Optimize) 엔진이 없습니다. 사용자는 각 RDD를 직접 최적화 해야 합니다.
등등의 이유로 인하여, 스파크 진영에서는 RDD의 한계를 극복하기 위해 DataFrame이라는 개념을 도입합니다.
DataFrame의 특징
그럼 DataFrame 구조가 기존 RDD와의 차별점으로 가지고 있는 특징에는 어떤 것들이 있을까요?
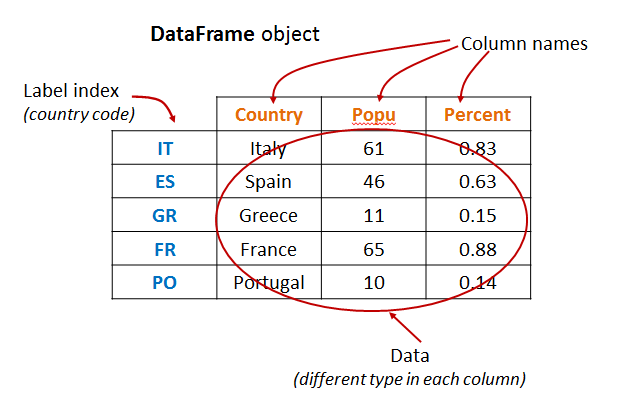
- 구조화된(structed) 데이터 구조 : 앞서 언급한 것처럼, DataFrame은 구조화된 데이터를 다루기 쉽게 하기 위해 만들어진 데이터 구조 입니다. 이를 통해, 스파크 사용자는 SparkSQL 등을 통해 구조화된 데이터의 쿼리를 처리할 수 있습니다.
- GC(Garbeage Collection) 오버헤드 감소 : RDD는 데이터를 메모리에 저장합지만, DataFrame은 데이터를 오프-힙(gc의 영향을 받지 않는, 디스크가 아닌 RAM 영역) 영역에 저장합니다. 이를 통해 Garbage Collection의 오버헤드를 감소시켰습니다.
- 직렬화 오버헤드 감소 : DataFrame은 오프-힙 메모리를 사용한 직렬화를 통하여 오버헤드를 크게 감소시켰습니다.
- Flexibility & Scalability : DataFrame은 CSV, 카산드라(Cassandra) 등 다양한 형태의 데이터를 직접 지원합니다. 사용자 입장에서는 이를 통한 효율성이 매우 큽니다.
♣♣♣
이처럼 DataFrame의 등장 이후, 구조화된 데이터의 처리 영역에서의 강점 덕분에,
스파크 기반의 SQL이 가능해졌다는 것 만으로도 큰 Benefit이 있었습니다.
더 나아가, 주로 정형화된 데이터셋을 다루는(최근의 경향은 좀 달라지긴 했습니다만...)
스파크의 MLlib 분야에서도 큰 강점을 지니게 되었죠.
자 이렇게 오늘은
Spark 데이터 구조 중, DataFrame에 대해 알아보았습니다.
다음 포스트는 Spark 데이터 구조의 마지막 챕터, DataSet 입니다.
그럼 다음 포스트에서 보자구요오오오오
