
<ETL ELT 차이>
안녕하세요.
개발자 김모씨입니다.
오늘의 이야기는 ETL, ELT에 관한 이야기입니다.
ETL.
데이터와 밀접한 분야에서 일하고 계신 분들은 많이 들어보셨을 겁니다.
최근엔 'ETL 시대의 종말'이라고 할 정도로,
ETL에서 ELT로 흐름이 바뀌고 있죠.
그래서 오늘은,
ETL과 ELT는 무엇이고
왜 이러한 변화의 흐름이 생겨났는지에 대해 이야기해보겠습니다.
ETL이란?

보통 데이터 엔지니어 또는 데이터베이스 엔지니어의 일은 ETL에서 시작한다고 해도 과언이 아닙니다.
ETL이란 Extract, Transform, Load 세 단어의 축약어죠.
각각의 의미를 살펴보면,
- Extract : 소스 data로부터 추출
- Transform : DeNomalize 등의 추출된 데이터 변형
- Load : DW(DataWarehouse)로의 데이터 적재
로 설명할 수 있습니다.
스텝별로 다시 설명하자면
1. 필요한 raw data를 꺼낸다.
2. 용도에 맞게 필터링/정형(reshaping)/정제 등의 단계를 수행한다.
3. 정제된 데이터를 데이터웨어하우스에 적재한다.
의 단계를 거치게 됩니다.
왜 ETL 단계가 필요하냐구요?
데이터웨어하우스는 소스 시스템 또는 환경에서 추출된 그대로의 raw data를 처리할 수 없습니다.
이 데이터를 분석한다거나 사용하기 위해서는 반드시 변환(Transform) 단계가 필요하죠.
뿐만 아니라, raw data 중 수많은 레거시 데이터를 필터링 해내는 작업도 꼭 필요합니다.
ETL 단계의 핵심은 Transform 단계에 있습니다.
비즈니스 또는 분석 용도에 맞춰 데이터를 정제하는 단계를 잘 설계해야 하죠.
용도가 바뀐다거나, 데이터웨어하우스의 구조가 바뀐다거나 하는 등의 이슈는
Transform 단계 전체를 무력화 시킬 수 있습니다.
'쓸모 없다' 판단했던 데이터가 '쓸모 있다'로 바뀌거나 그 반대의 경우가 발생하기 때문이죠.
그래서 그에 맞춰 Transform 로직을 변형하고, 데이터를 re-processing 한 후 재적재 하여야 합니다.
당연히 데이터 크기가 크면 클수록, Transform에 소요되는 시간도 비례해서 커지게 되죠.
위 그림과 같은 Logical한 ETL 파이프라인이 설계된 후에는
1일 1회 등의 방식으로 전일의 로그 데이터와 유의미한 데이터 셋은 새로운 DB에 저장할 수 있습니다.
그러면 데이터 사이언티스트 또는 데이터 애널리스트들이 해당 DB에 접근하여 분석하는 거죠.
ETL과 ETL에 맞춰진 파이프라인은
기업의 데이터가 크면 클수록 매우 Critical한 전략 중 하나였습니다.
현재도 수많은 기업들이 이러한 방식을 그대로 사용하고 있죠.
ELT란?
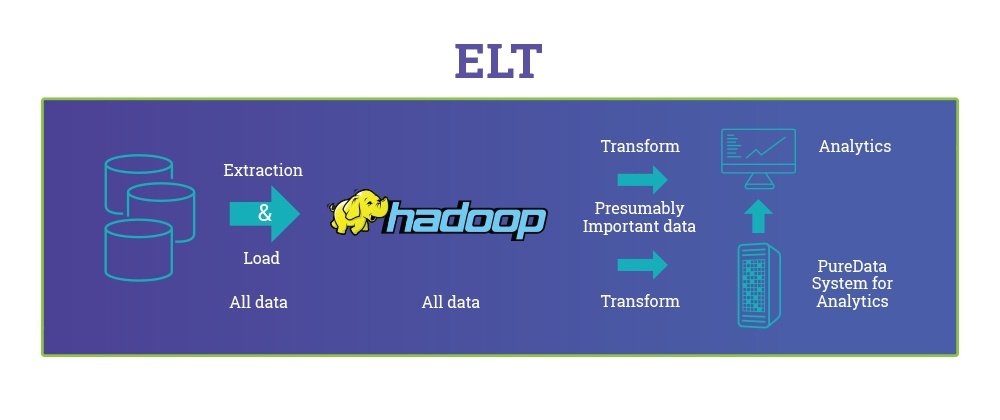
그런데, 최근 변화가 생기기 시작했습니다.
위에서 E/T/L 각각의 의미에 대해 말씀드렸죠.
T와 L의 위치가 바뀐,
ELT라는 새로운 개념이 등장했습니다.
추출하고, 적재한 후에 변형하자는 의미죠.
다시 말하면,
기존 ELT처럼 데이터를 적재하기 전에 먼저 변형하는 것 대신에,
타겟시스템 또는 툴이 직접 데이터를 변형하게 하자! 라는 방식입니다.
데이터를 추출한 후 즉시 로드(적재) 단계를 시작하여,
모든 데이터 소스를 하나의 공간에 이동시킵니다.
여기서 HDFS 등이 사용될 수 있겠죠.
그 후, 용도에 따라서 필요할 경우에 데이터를 변형하여 사용하는 거죠.
Why?
데이터 프로세싱의 혁신이라고 까지 부를 수 있을 정도인
이러한 변화는 왜 발생했을까요?
1. 대량의 데이터가 발생하기 시작하였습니다.
앞서 언급하였듯, ETL 방식의 경우 Transform에서 대부분의 시간이 소요됩니다.
최근 4차산업혁명이다, 디지털 트랜스포메이션이다 해서
정형 + 비정형의 수많은 데이터가 실시간으로 생성되고 소멸되고 있죠?
이러한 환경에서 ETL 방식이 근실시간성의 대규모 데이터를 감당할 수 있을까요?
그래서 사람들은 생각합니다.
"우선 데이터를 다 저장해두자! 어디에 어떻게 쓸 것인지는 나중에 고민하자"
그래서 생겨난 것이 Data Lake라는 개념입니다.
마치 호수처럼,
모든 데이터를 다 저장해두고 용도에 따라 가져다 쓰자 라는 논리죠.
ELT는 이처럼,
대량의 데이터를 가진 환경에서 Data Lake를 지원하기 위해 많이 사용됩니다.
2. 리소스들의 가격 인하
이러한 변화가 생기게 된 근본적인 이유가 아닐까 생각합니다.
과거 10여년 전만 돌이켜보아도,
CPU, 메모리, SSD, HDD 등의 리소스 가격이 많이 다운되었죠.
이와 같은 물리 리소스들은 물론이거니와,
AWS, GCP 등의 Cloud 환경 이용료도 눈에 띌 정도로 인하되었습니다.
그래서 사람들은 생각합니다.
"기존엔 저장 공간이 부족해서, 분석을 위한 CPU 성능이 부족해서 데이터를 미리 변환/정제 해야 했는데,
이 정도 가격이라면 전부 다 저장해버리는 게 더 낫겠네!"
"데이터를 더 많이 만들어내고, 더 많이 분석하자!"
결과적으로 리소스들의 가격 인하는
데이터 붐을 일으켰고, ELT로의 전환에까지 이르렀습니다.
그래서, ETL은 죽었을까요?
우리는 과연 이 변화를 'ETL의 죽음'이라고 부를 수 있을까요?
가벼운 변환 작업, 1차적인 데이터 정제 및 레거시 필터링 등의 용도에서
여전히 ETL은 꽤 많이 사용되고 있습니다.
데이터 엔지니어 또는 데이터베이스 엔지니어에게
ETL 스킬은 여전히 필수덕목이죠.
그러나
기존의 방식을 깨부수고
ELT 방식으로 빠르게 변화한 기업들은
BI, Analytics 팀들이 좀 더 빠르고 유연하게 움직일 수 있는 환경을 만들었습니다.
그 결과, 지금 이 순간에도 경쟁 기업들을 앞서 나가고 있죠.
여기까지
ETL과 ELT는 무엇이고,
왜 이러한 변화가 생겨났는지에 대해 알아보았습니다.
개발자라는 직업은
항상 변화에 민감하고 새로운 기술을 받아들일 준비가 되어있어야 한다는 걸
새삼스레 다시 느낍니다.
그럼 오늘은, 여기까지.
감사합니다.

'IT이야기 > IT 상식' 카테고리의 다른 글
| Blue Green 배포 (Feat. 무중단 배포) (3) | 2020.09.23 |
|---|---|
| A/B 테스트란? (알파베타 테스트) (4) | 2020.09.22 |
| CI/CD란 무엇인가 (Feat. DevOps 엔지니어) (15) | 2020.09.21 |
| HTTP vs. HTTPS (Feat. HTTP와 HTTPS의 차이점) (2) | 2020.09.20 |




댓글